This article covers how to query topics with Kpow, the leading toolkit for Apache Kafka.
If you're new to Kpow, why not grab our free community edition and dive into this article to supercharge your Kafka querying skills.
Get started now and experience the unparalleled power of Kpow's querying capabilities firsthand!
Introduction
Querying Kafka topics is a critical task for engineers working on data streaming applications, but it can often be a complex and time-consuming process.
Whether you're a developer prototyping a new feature or an infrastructure engineer ensuring the stability of a production environment, having a powerful querying tool at your disposal can make all the difference. Enter Kpow's data inspect feature—designed to simplify and optimize Kafka topic queries, making it an essential tool for professionals working with Apache Kafka.
Overview
Apache Kafka and its ecosystem have emerged as the cornerstone of modern data-in-motion solutions. Our customers leverage a variety of technologies, including Kafka Streams, Apache Flink, Kafka Connect, and custom services using Java, Go, or Python, to build their data streaming applications.
Regardless of the technology stack, engineers need reliable tools to examine the foundational Kafka topics in their streaming applications. This is where Kpow's data inspect feature comes into play. Data inspect offers ad hoc, bounded queries across Kafka topics, proving valuable in both development and production scenarios. Here’s how it can be particularly useful:
Key use cases in development
- Validating data structures: Verifying and validating the shape of data (both key and value) during the prototyping phase.
- Monitoring message flow: Ensuring that messages are flowing to the topic as expected and that topic message distribution is well balanced across all partitions.
- Debugging and troubleshooting: Identifying and resolving issues in the development phase. For example validating that your topic's configuration is applying its compaction policy as expected or that segments are being deleted as expected.
Critical applications in production
- Identifying poison messages: Quickly identifying and addressing messages that can cause downstream issues that may have caused consumer groups to break.
- Reconciliation and Analytics: Querying for specific events for reconciliation or analytic purposes.
- Monitoring and Alerting: Keeping track of Kafka topics for anomalies or unusual activity.
- Compliance and Auditing: Ensuring compliance with data governance standards and auditing access to sensitive data.
- Capacity Planning: Planning and scaling infrastructure based on the volume and velocity of data flowing through topics.
This article will dive into the technical details of Kpow's data inspect query engine and how you can maximise your own querying in Kafka. Whether you're a developer looking to validate data during development or part of the infrastructure team tasked with ensuring the stability and performance of your production Kafka clusters, data inspect offers a powerful set of tools to help you get the most out of your Kafka deployments.
Introduction to Data Inspect
Kpow’s data inspect gives teams the ability to perform bounded queries across one or more Kafka topics. A bounded query retrieves a specific range or subset of data from a Kafka topic, informed by user input through the data inspect form. Users can specify:
- A Date Range: An ISO 8601 date range specifying the start and end bounds of the query.
- An Offset Range: The start offset from where you'd like the query to begin (especially useful when searching against a partition or key).
Kpow’s data inspect form simplifies the querying process by offering common query options as defaults. For instance, to view the most recent messages in a topic, Kpow's default query window is set to 'Recent' (e.g., the last 15 minutes). Users can also specify custom date times or timestamps for more fine-grained queries.
Additionally, the data inspect form allows input of topic SerDes and any filters to apply against the result set, which will be explained below.
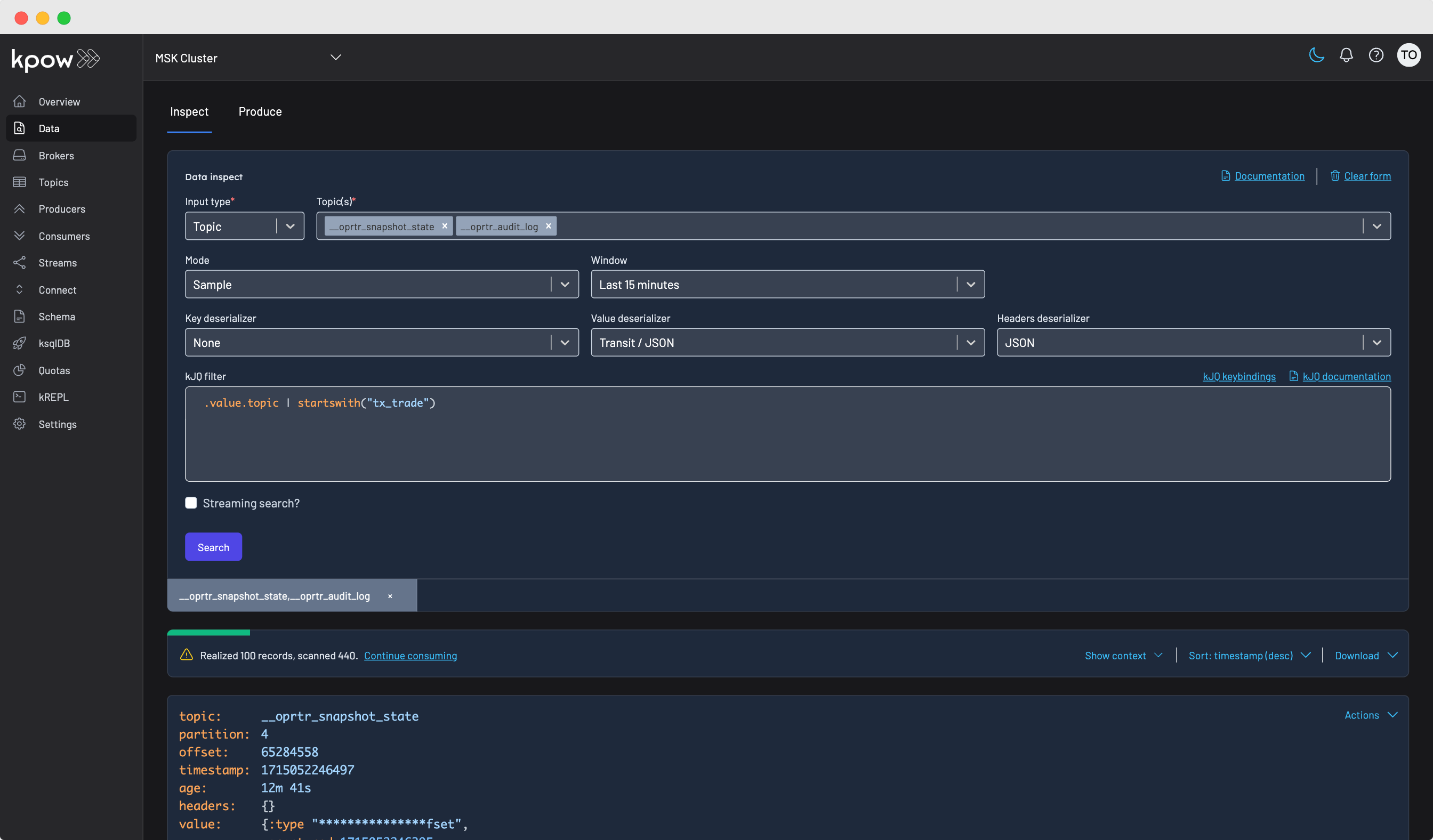
The Query Plan
Once all inputs are provided, Kpow constructs a query plan similar to that of a SQL engine. This plan optimizes the execution of the query and efficiently parallelizes queries across a pool of consumer groups. It’s this query engine that powers Kpow’s blazingly fast multi-topic search.
The query engine ensures an even distribution of records from all topic partitions when querying. An even distribution is crucial for understanding a topic's performance because it ensures that the analysis is based on a representative sample of the data. If certain partitions are overrepresented, the analysis may be skewed, leading to inaccurate insights.
The cursors table, part of the data inspect result metadata, displays the comprehensive progress of the query, detailing the start and end offsets for each topic partition, the number of records scanned, and the remaining offsets to query.
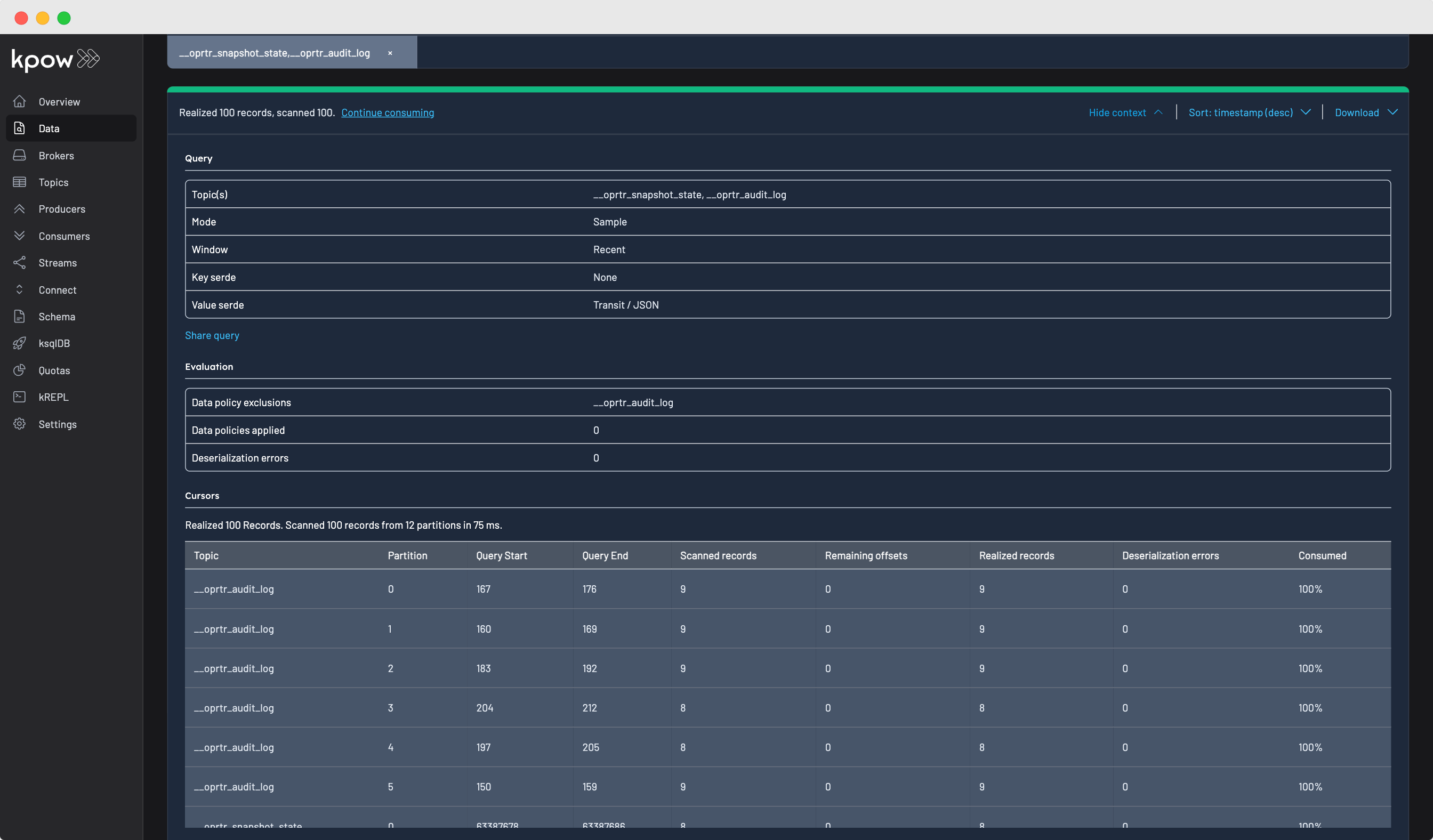
We understand your data
Kpow supports a wide-array of commonly used data formats (known as SerDes). These formats include:
- JSON
- AVRO
- JSON Schema
- Protobuf
- Clojure formats such as EDN or Transit/JSON
- XML, YAML and raw strings
Kpow integrates with both Confluent's Schema Registry and AWS Glue. Our documentation has guides on how you can configure Kpow's Schema Registry integration.
If we don't support a data format you use (for example you use Protobuf with your own encryption-at-rest) you can import your own custom SerDes to use with Kpow. Visit our documentation to learn more about custom SerDes.
jq filters for Kafka
No matter which message format you use, filtering messages in Kpow works transparently across every deserializer.
kJQ is the filtering engine we have built at Kpow. It's a subset of the jq programming language built specifically for Kafka workloads, and is embedded within Kpow's data inspect.
jq is like sed for JSON data - you can use it to slice and filter and map and transform structured data with the same ease that sed, awk, grep and friends let you play with text.
Instead of creating yet another bespoke querying language that our customers would have to learn, we chose jq, one of the most concise, powerful, and immediately familiar querying languages available.
An example of a kJQ query:
.key.currency == "GBP" and
.value.tx.price | to-double < 16.50 and
.value.tx.pan | endswith("8649")
If you are unfamiliar with jq, or want to learn more we generally recommend the following resources:
- jq playground: an online interactive playground for jq filters.
- Kpow's kREPL: Kpow has a built in REPL. It is our programmatic interface into Kpow's data inspect functionality. Within the kREPL you can experiment with kJQ queries - much like the jq playground.
- Kpow's kJQ documentation: a quick guide on kJQ's grammar, including examples.
While the kREPL is out of scope for this blog post, stay tuned for future articles where we’ll take a deep dive into how you can use kJQ to construct sophisticated filters and data transformations right within Kpow.
Enterprise security built-in
Filtering data is only part of the equation. In order to perform ad-hoc queries against production data, Kpow provides enterprise-grade security features:
Role-Based Access Control (RBAC)
Kpow’s declarative RBAC system is defined in a YAML file, where you can assign policies to user roles authenticated from an external identity provider (IdP). This allows you to permit or deny access to Kafka topics based on user roles.
For example:
policies:
- resource: [ "cluster", "confluent-cloud1", "topic", "tx_trade_*" ]
effect: "Allow"
actions: [ "TOPIC_INSPECT" ]
role: "dev"
- resource: [ "*" ]
effect: "Allow"
actions: [ "TOPIC_INSPECT" ]
role: "admin"
The above RBAC policy defines that:
- Any user assigned to the
devrole will have access to any topic starting withtx_trade_*for only theconfluent-cloud1cluster. All other topics will be implicitly denied. - Any user assigned to the
adminrole will have access to all topics for all clusters managed by Kpow. - All other users are implicitly denied access to data inspect functionality.
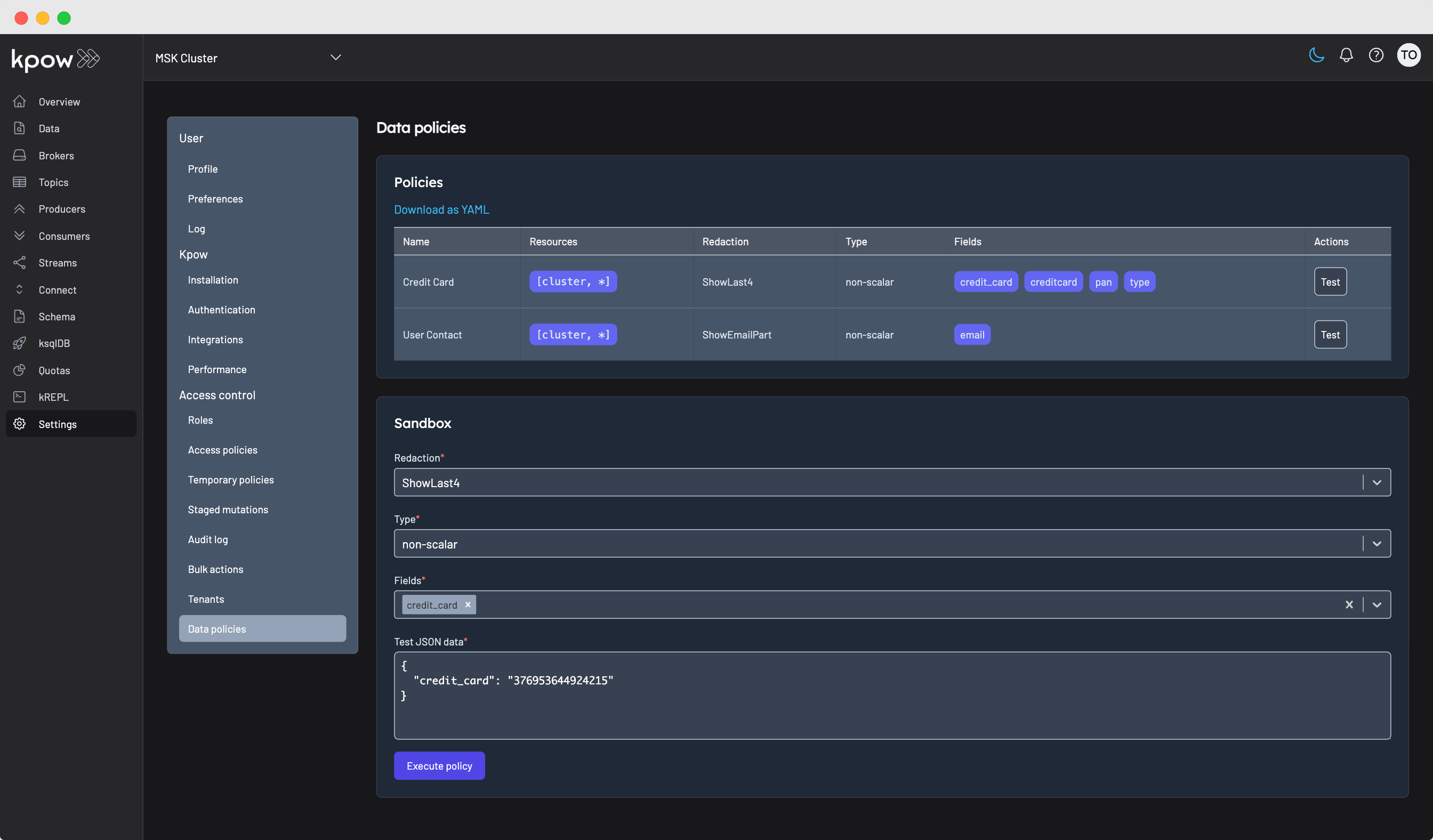
Data Masking
In environments where compliance with PII requirements is mandatory, data masking is essential. Kpow’s data masking feature allows you to define policies specifying which fields in a message should be redacted in the key, value, or headers of a record. These policies apply to nested data structures or arrays within messages. For instance, a policy might:
- Show only the last 4 characters of a field (ShowLast4)
- Show only the email host (ShowEmailHost)
- Return a SHA hash of the contents (SHAHash)
- Fully redact the contents (Full)
Kpow provides a data masking sandbox where users can validate policies against test data, ensuring that redaction methods work as expected before deploying them.
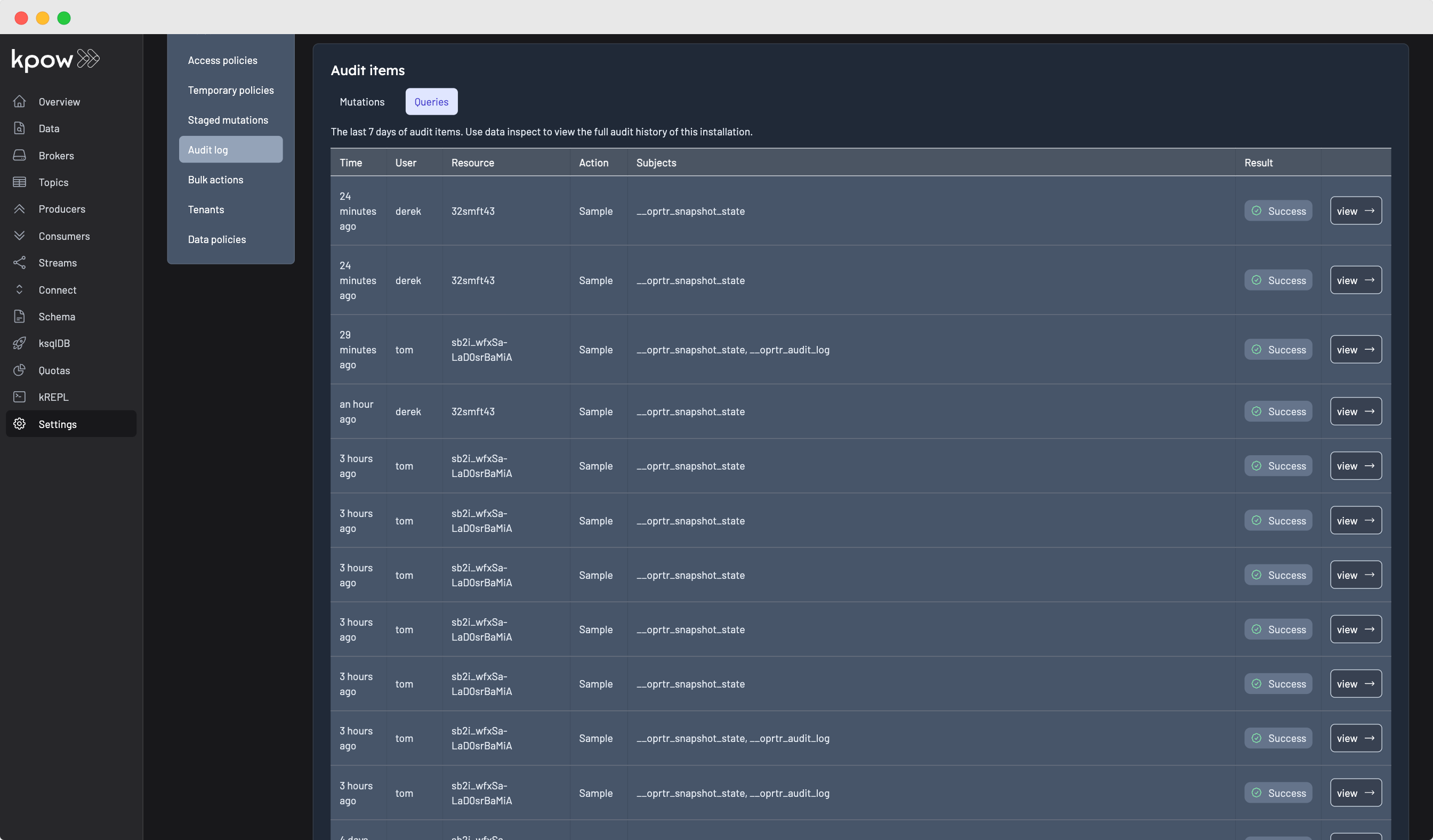
Data Governance
Maintaining a comprehensive audit log is crucial for ensuring data governance and regulatory compliance. Kpow's audit log records all queries performed against topics, providing a detailed trail of who accessed the data, what topics were accessed, and when the query occurred. This information is vital for monitoring and enforcing data security policies, detecting unauthorized access, and demonstrating compliance with regulations such as GDPR, HIPAA, or PCI DSS. Within Kpow’s admin UI, navigate to the "Audit Log" page and then to the "Queries" tab to view all queries performed using Kpow.
Within Kpow's admin UI you can navigate to the "Audit log" page and then to the "Queries" tab to view all queries that have been performed using Kpow.
Getting started today
Kpow's data inspect feature revolutionizes the way professionals work with Apache Kafka, offering a comprehensive toolkit for querying Kafka topics with ease and efficiency. Whether you're validating data structures, monitoring message flow, or troubleshooting issues, Kpow provides the tools you need to streamline your workflow and optimize your Kafka-based applications.
Ready to take your Kafka querying to the next level? Sign up for Kpow's free community edition today and start exploring the power of Kpow's data inspect feature. Experience firsthand why Kpow is the number one toolkit for Apache Kafka and unlock new possibilities for managing and optimizing your Kafka clusters.