Overview
The theLook eCommerce dataset is a valuable resource for data professionals. It provides a realistic, comprehensive schema for testing analytics queries and BI tools. However, it has one major limitation: it's static. It's a snapshot in time, designed for traditional batch workloads.
Modern data applications thrive on live, event-driven data. From real-time dashboards to responsive microservices, the ability to react to data as it changes is essential. How can we practice building these systems with a dataset that feels real?
To solve this, we've re-engineered theLook eCommerce data into a real-time, streaming data source. This project transforms the classic batch dataset into a dynamic environment for building and testing Change Data Capture (CDC) pipelines with Debezium and Kafka.
💡 The complete project, including all source code and setup instructions, is available on GitHub.
⚡ Looking for more hands-on labs and projects? Check out our previous posts: Introduction to Factor House Local and Building a Real-Time Leaderboard with Kafka and Flink to level up your streaming data skills.
What is Change Data Capture (CDC) with Debezium?
Change Data Capture is a design pattern for tracking row-level changes in a database (INSERT, UPDATE, DELETE) and making them available as an event stream. Instead of repeatedly querying a database for updates, CDC systems read the database's transaction log directly, capturing every committed change as it happens.
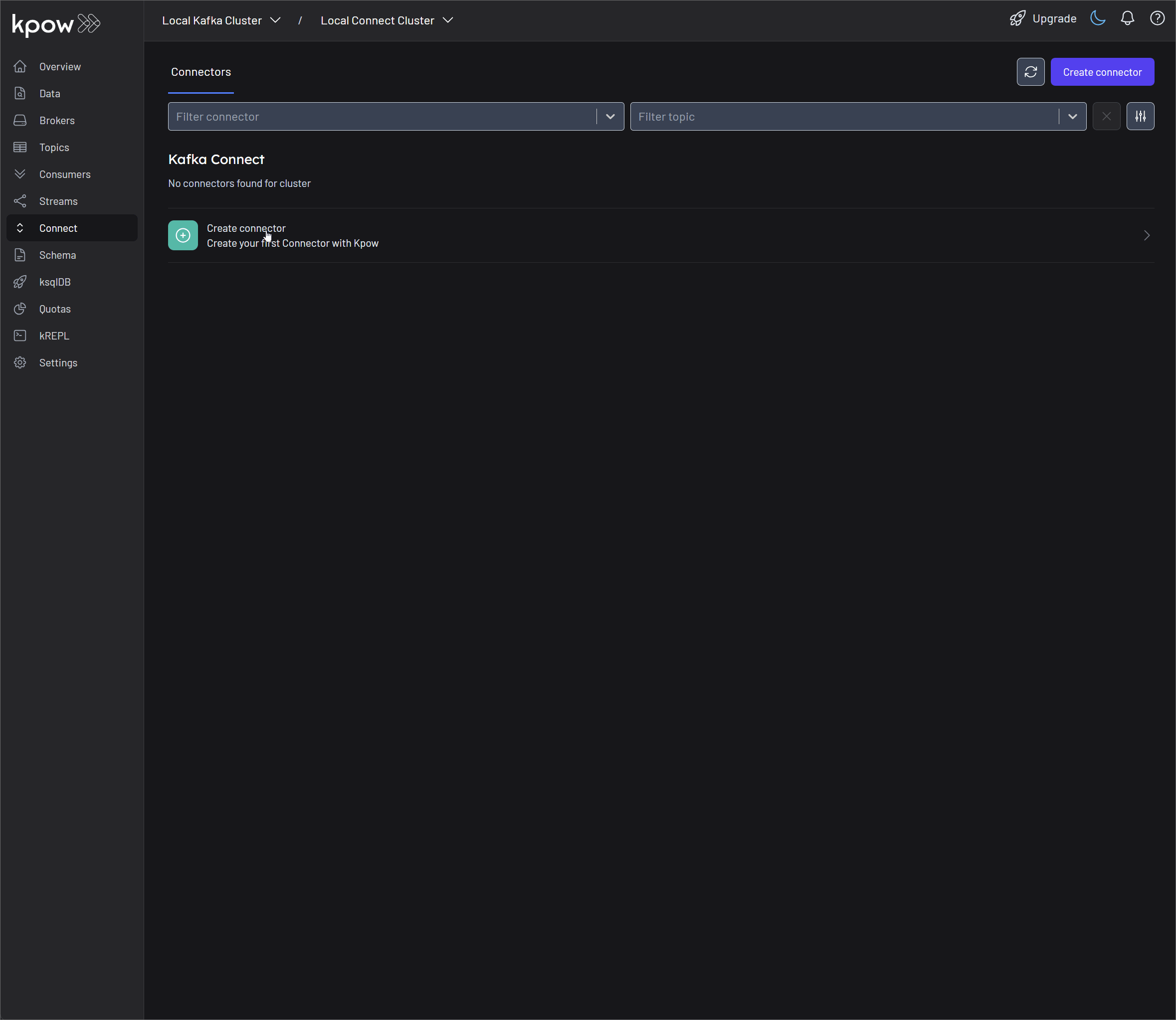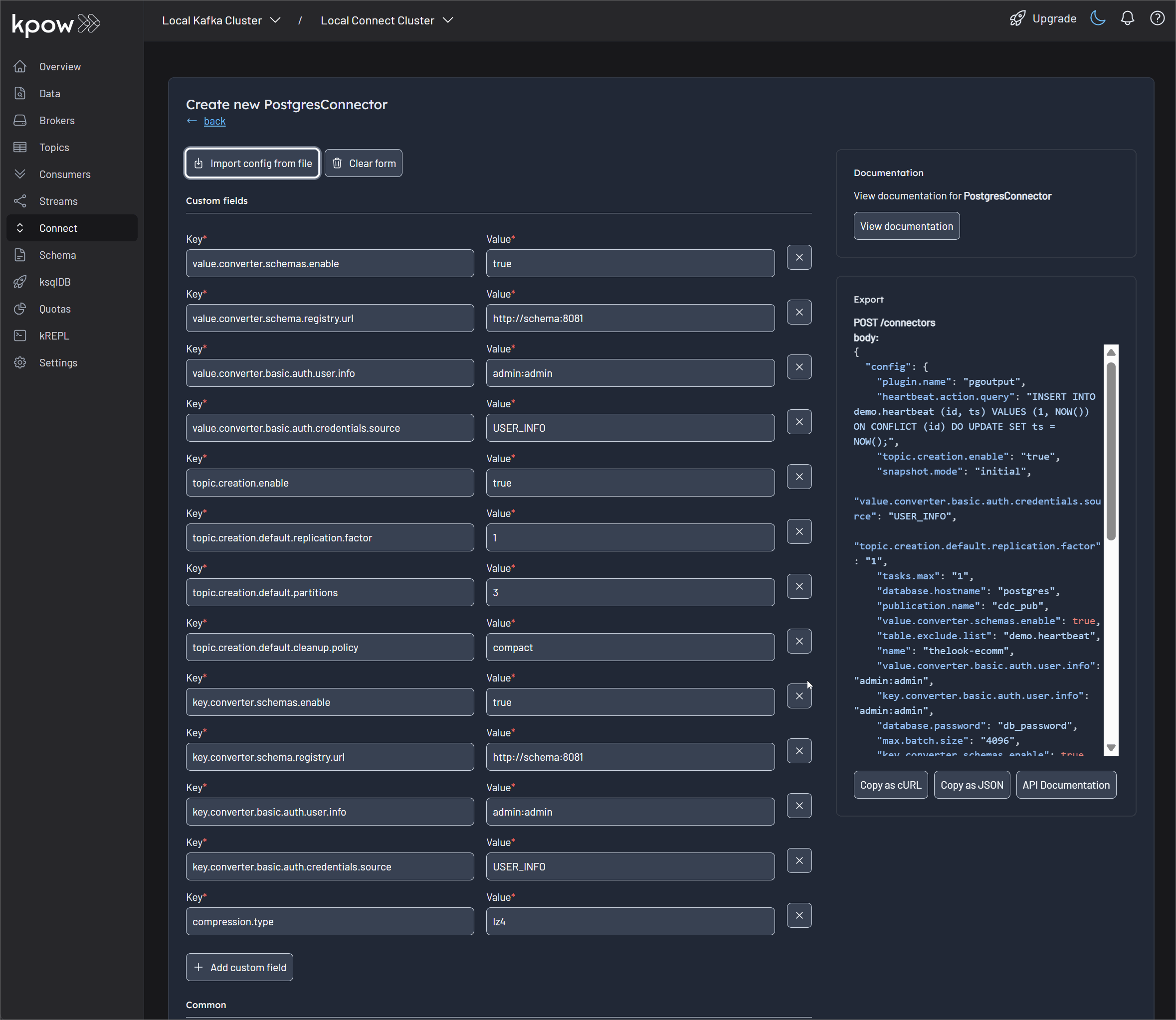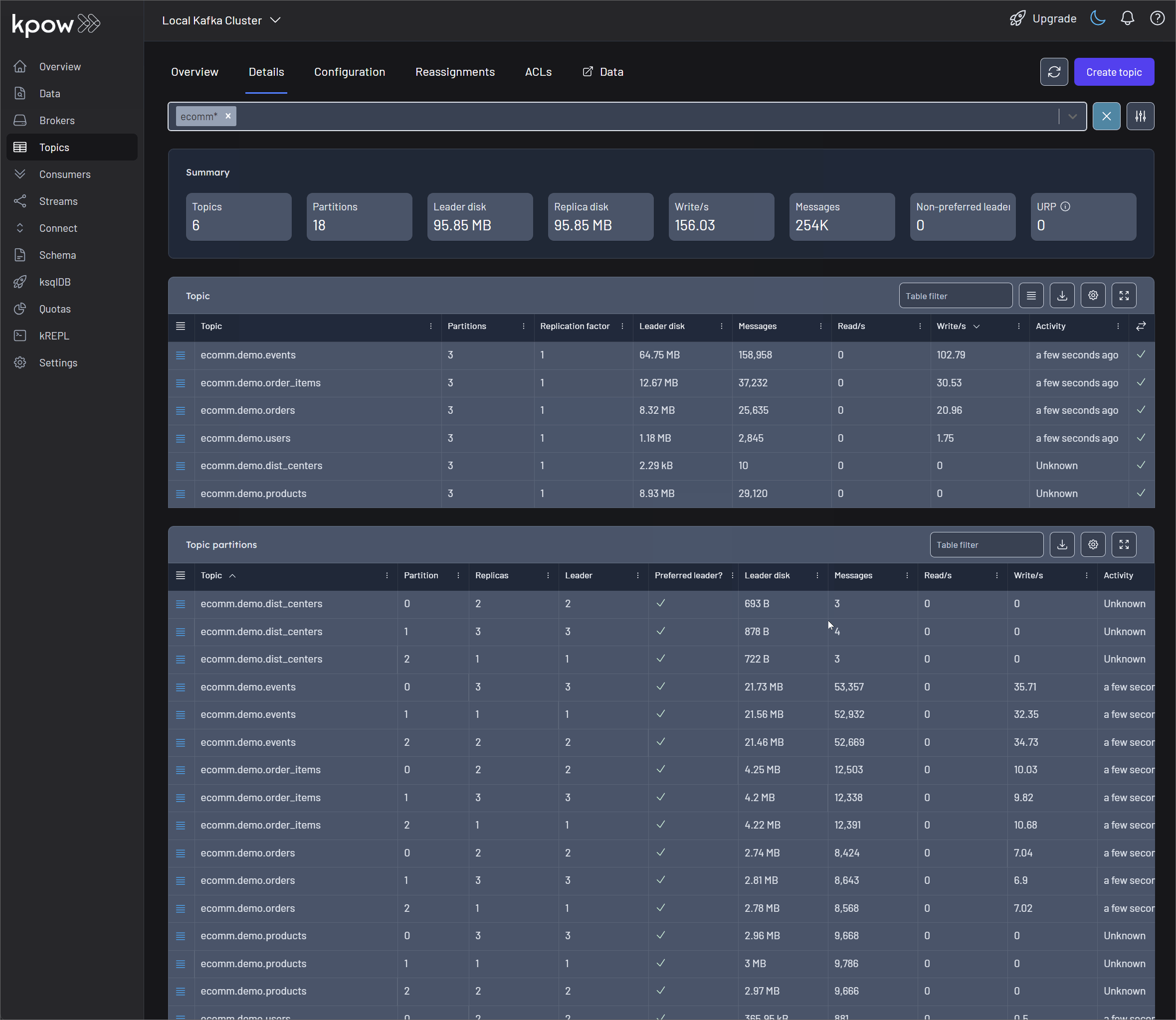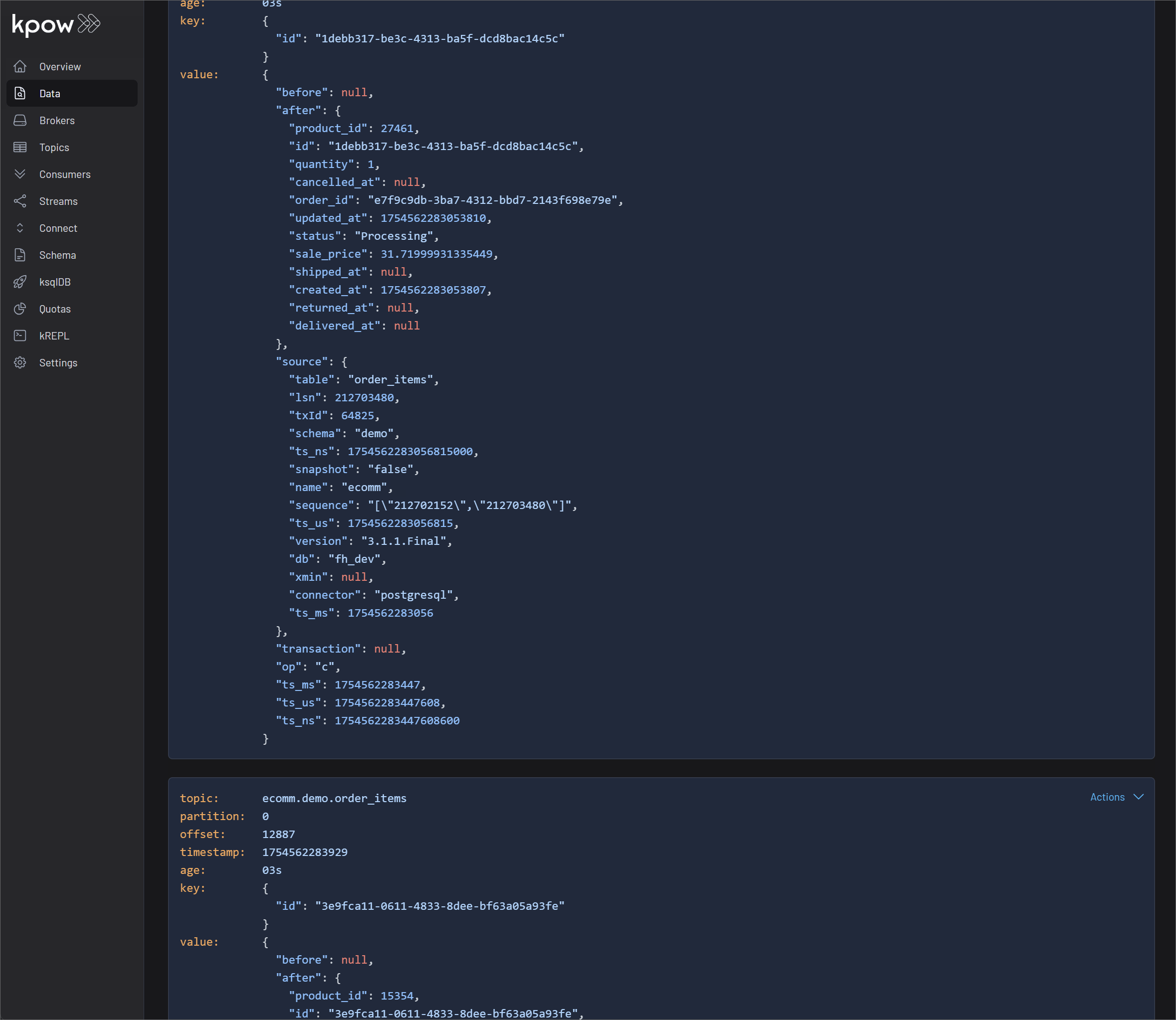
Debezium is a leading open-source, distributed platform for CDC. It provides a library of connectors that turn your existing databases into event streams. In this project, we use the Debezium PostgreSQL connector, which works by reading the database's write-ahead log (WAL). To enable this, the PostgreSQL server's wal_level is set to logical, which enriches the log with the detailed information needed for logical decoding.
With the Debezium PostgreSQL connector, we can use PostgreSQL's built-in pgoutput logical decoding plugin to stream the sequence of changes from the WAL. It operates on a push-based model, where the database actively sends changes to the Debezium connector as they are committed. The connector then processes these changes and pushes them as events to Kafka topics, ensuring low-latency data streaming.
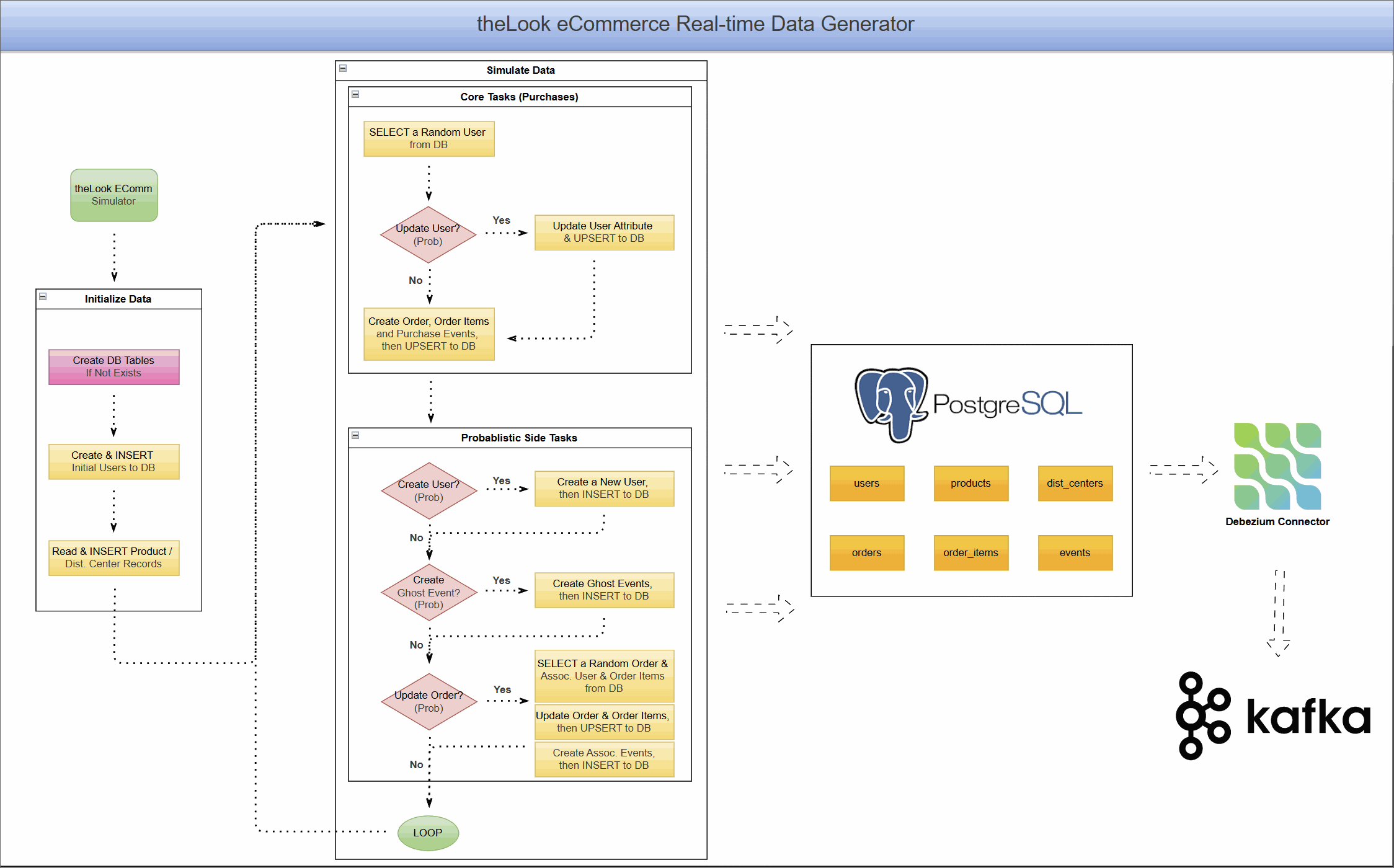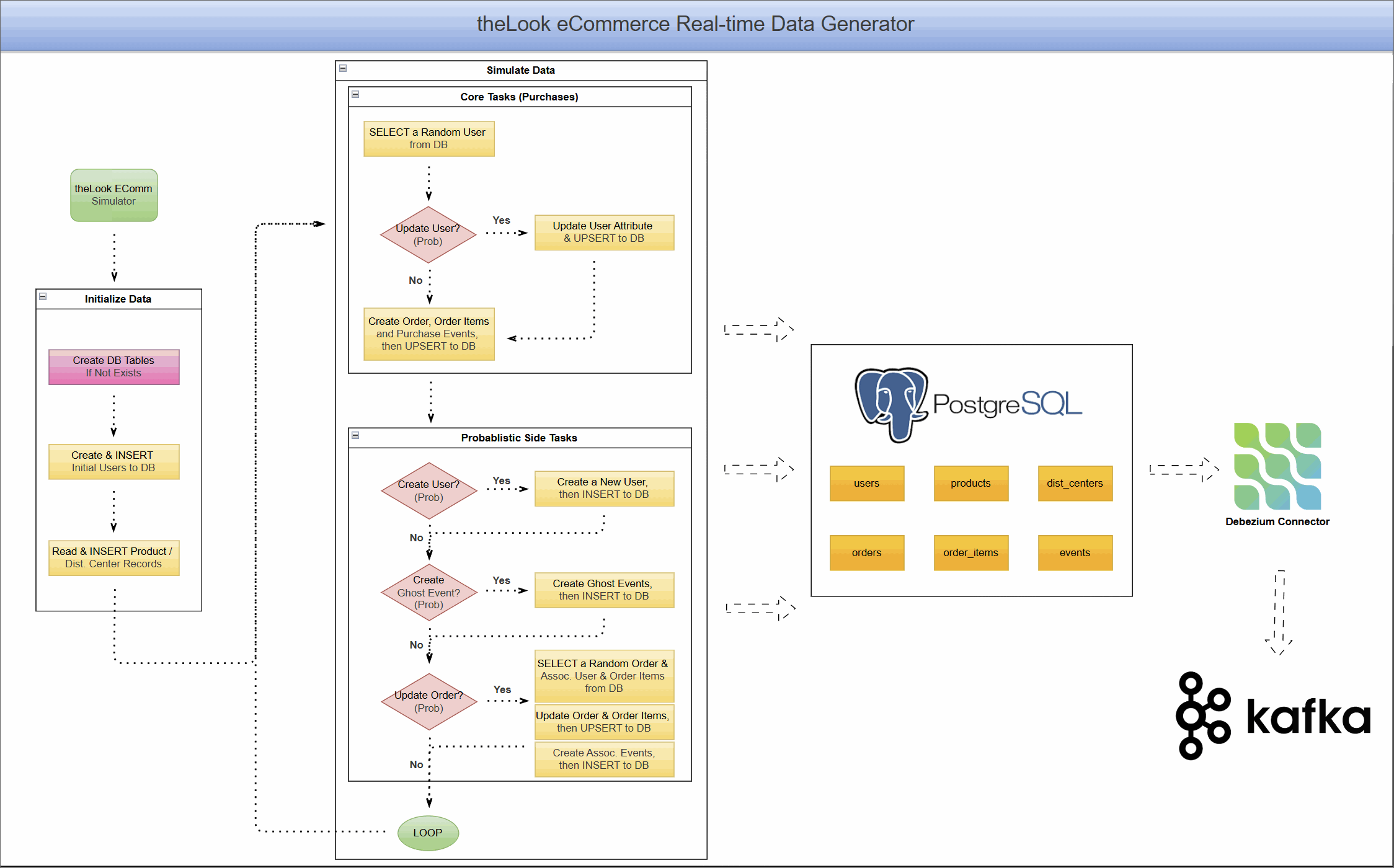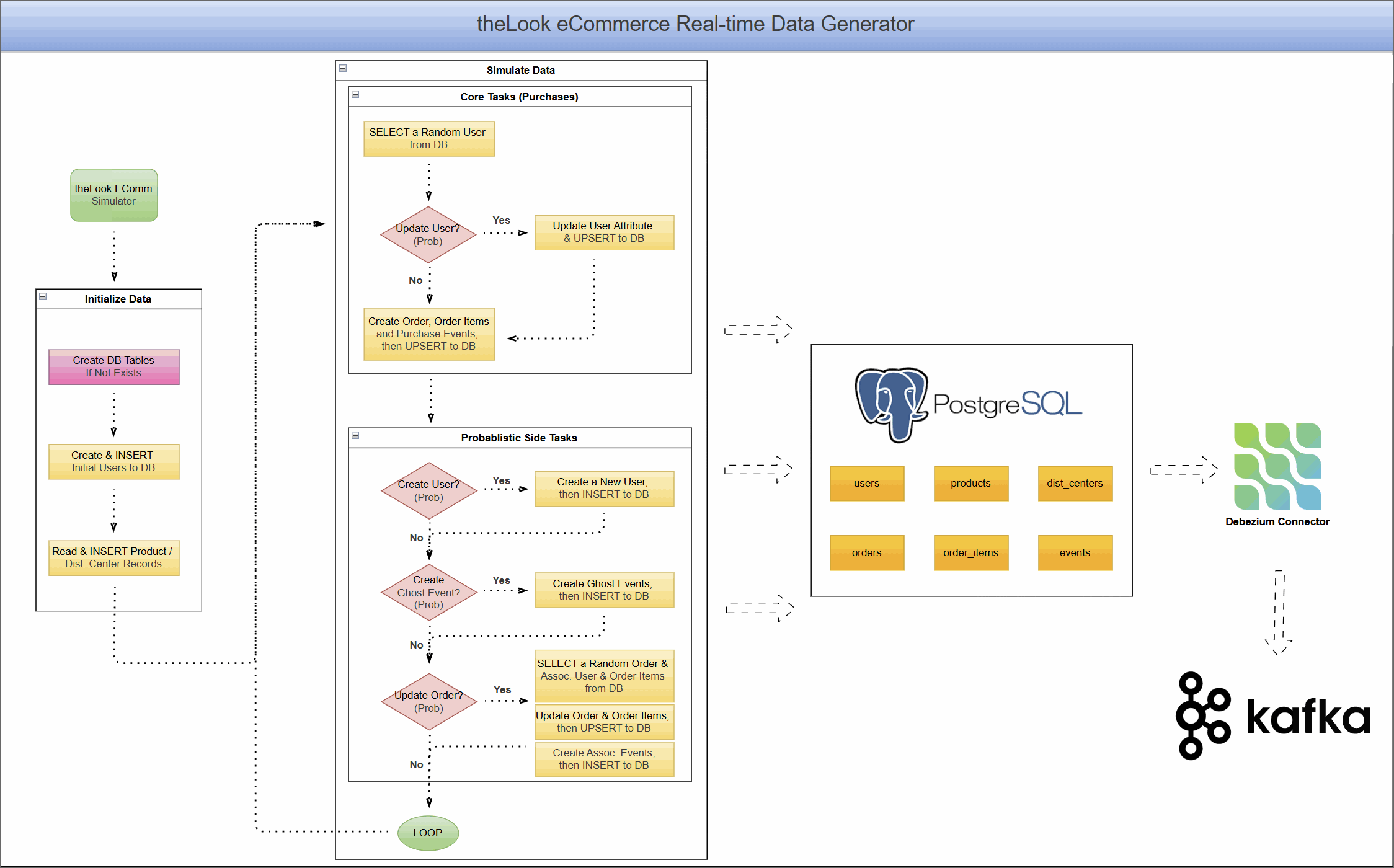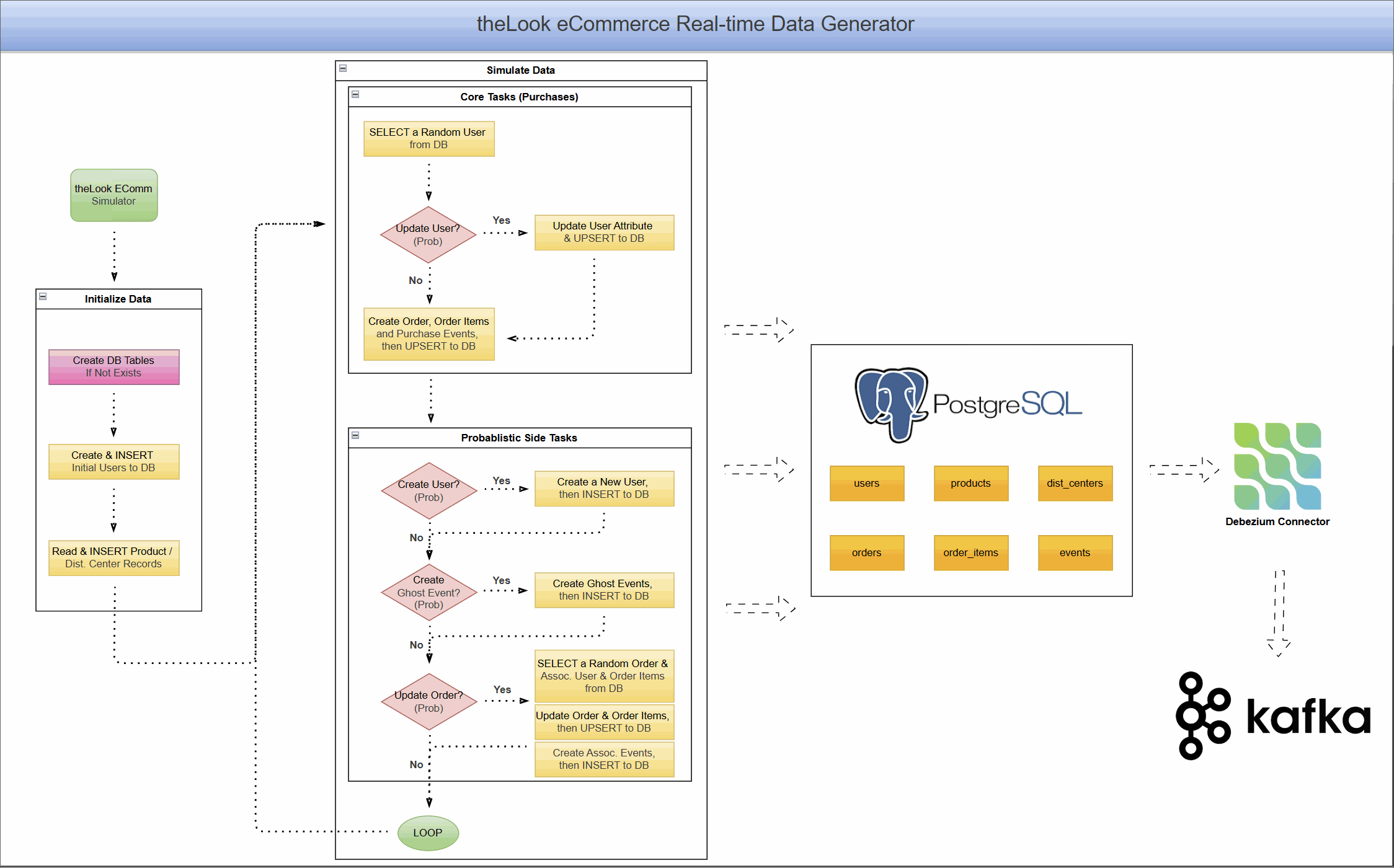
Project Architecture: A Live eCommerce Store in a Box
This project combines a dynamic data generator with a complete CDC pipeline, allowing you to see the end-to-end flow of data.
Real-Time Data Generator
At the heart of the project is a Python-based simulator that brings theLook eCommerce dataset to life. It:
- Simulates continuous user activity, including new user sign-ups, product browsing, purchases, and even order updates like cancellations or returns.
- Writes this data directly into a PostgreSQL database, creating a constantly changing, realistic data source.
- Models complex user journeys, from anonymous browsing sessions to multi-item orders.
This component transforms PostgreSQL from a static warehouse into a transactional database that mirrors a live application.
CDC Pipeline with Debezium and Kafka
With data flowing continuously into PostgreSQL, we can now capture it in real-time.
- The PostgreSQL database is prepared with a
PUBLICATIONfor all tables in our eCommerce schema. This publication acts as a logical grouping of tables whose changes should be made available to subscribers, in this case, the Debezium connector. - A Debezium PostgreSQL connector is deployed and configured to monitor all tables within the schema.
- As the data generator writes new records, Debezium reads the WAL, captures every
INSERT,UPDATE, andDELETEoperation. - It then serializes these change events into Avro format and streams them into distinct Kafka topics for each table (e.g.,
ecomm.demo.users,ecomm.demo.orders).
The result is a reliable, low-latency stream of every single event happening in your e-commerce application, ready for consumption.
Why is This a Good Way to Learn?
This project provides a sandbox that is both realistic and easy to manage. You get hands-on experience with:
- Realistic schema: Work with interconnected tables for users, orders, products, and events—not just a simple demo table.
- Industry standard stack: Get familiar with the tools that power modern data platforms: PostgreSQL, Debezium, Kafka, and Docker.
- End-to-end environment: The entire pipeline is runnable on your local machine, giving you a complete picture of how data flows from source to stream.
What Can You Build With This?
A real-time stream of eCommerce events in Kafka opens up many possibilities for development. This project is the perfect starting point for:
- 🔍 Building real-time analytics dashboards with tools like Apache Flink or Apache Pinot to monitor sales and user activity as it happens.
- 🧊 Ingesting data into a lakehouse (e.g., Apache Iceberg) with Apache Flink to keep your warehouse continuously updated with real-time data.
- ⚙️ Developing event-driven microservices that react to business events. For example, you could build a
NotificationServicethat listens to theecomm.demo.orderstopic and sends a confirmation email when an order's status changes toShipped.
Get Started in Minutes
The entire project is containerized and easy to set up.
- Clone the factorhouse/examples repository from GitHub.
- Start the infrastructure (Kafka, PostgreSQL, etc.) using Docker Compose.
- Run the data generator via Docker Compose to populate the database.
- Deploy the Debezium connector and monitor Kafka topics as they are created and populated with real-time data.
We'd love to see what you build with this. Join the Factor House Community Slack and share what you're working on.
Conclusion
This project bridges the gap between static, batch-oriented datasets and the dynamic, real-time world of modern data engineering. It provides a practical, hands-on environment to learn, experiment, and build production-ready CDC pipelines with confidence.